Cheng-Chun Hsu
About Me
I am a Ph.D. student in Computer Science at the University of Texas at Austin. My research lies at the intersection of robotics and computer vision.
Publications [ Google Scholar]
-
 International Conference on Robotics and Automation (ICRA), 2025.
International Conference on Robotics and Automation (ICRA), 2025.
We enable robots to learn everyday tasks from human video demonstrations by usinbg object-centric representation. By predicting future object pose trajectories, SPOT achieves strong generalization capabilities with only eight human video demonstrations.
-
 Mobile Manipulation Workshop at ICRA, 2024.Spotlight Presentation
Mobile Manipulation Workshop at ICRA, 2024.Spotlight Presentation
We enable mobile manipulators to perform long-horizon tasks by autonomously exploring and building scene-level articulation models of articulated objects. It maps the scene, infers object properties, and plans sequential interactions for accurate real-world manipulation.
-
 International Conference on Robotics and Automation (ICRA), 2023.
International Conference on Robotics and Automation (ICRA), 2023.
We develop an interactive perception approach for robots to build indoor scene articulation models by efficiently discovering and characterizing articulated objects through coupled affordance prediction and articulation inference.
-
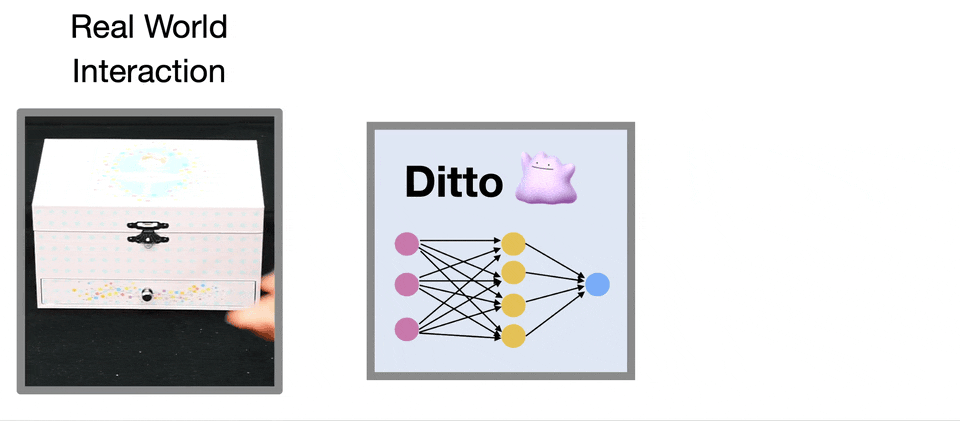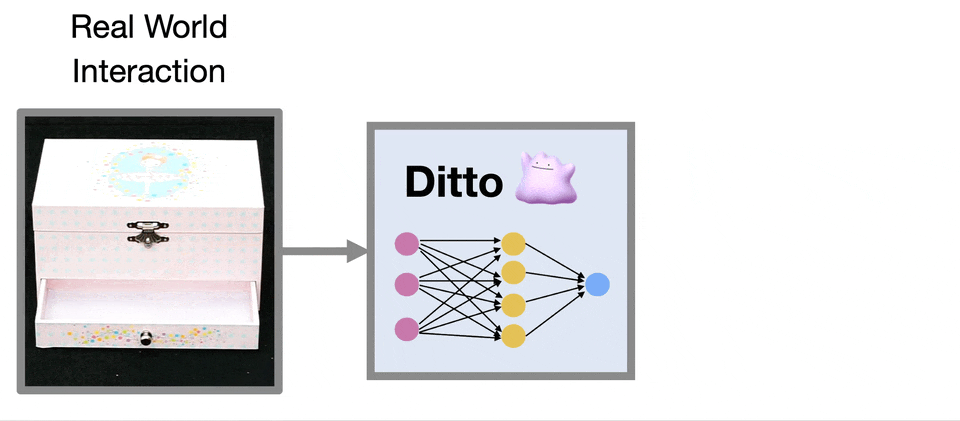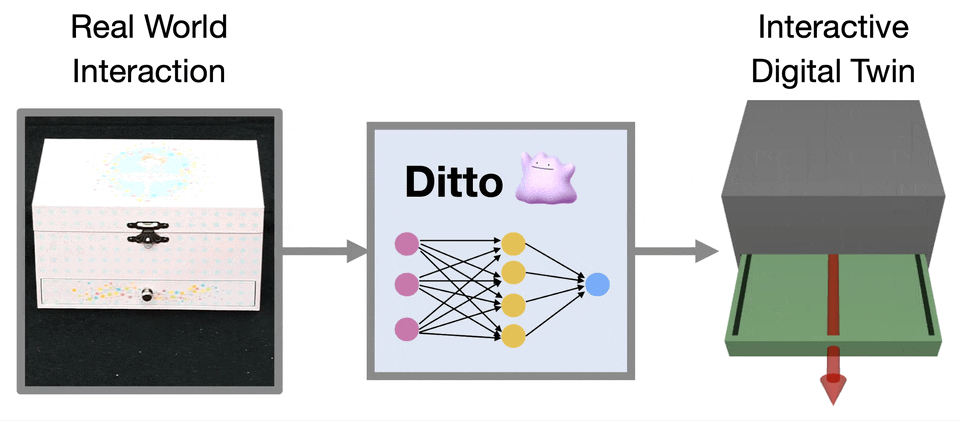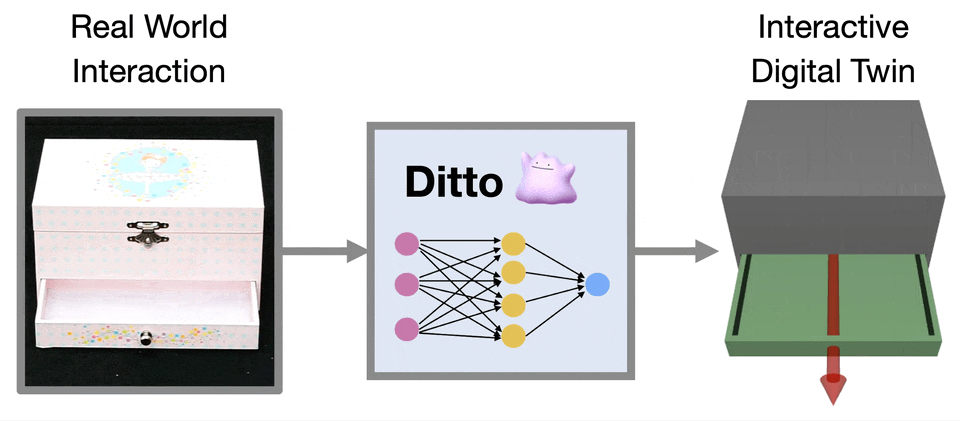 Computer Vision and Pattern Recognition (CVPR), 2022.Oral Presentation
Computer Vision and Pattern Recognition (CVPR), 2022.Oral Presentation
We develop an approach that builds digital twins of articulated objects by learning their articulation models and 3D geometry from visual observations before and after interaction.
-
 European Conference on Computer Vision (ECCV), 2020.
European Conference on Computer Vision (ECCV), 2020.
We propose a domain adaptation framework for object detection that uses pixel-wise objectness and centerness to align features, focusing on foreground pixels for better cross-domain adaptation.
-
 Neural Information Processing Systems (NeurIPS), 2019.
Neural Information Processing Systems (NeurIPS), 2019.
We propose a weakly supervised instance segmentation method that leverages Multiple Instance Learning (MIL) to address ambiguous foreground separation from bounding box annotations.
-
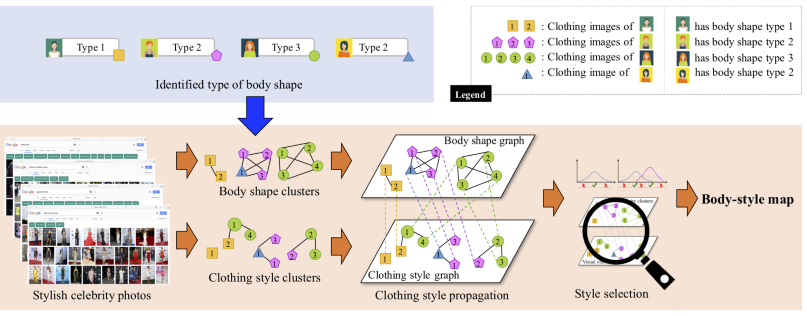 ACM International Conference on Multimedia (MM), 2018.Oral Presentation
ACM International Conference on Multimedia (MM), 2018.Oral Presentation
We propose to learn clothing style and body shape compatibility from social big data, offering personalized outfit recommendations by factoring in a user's body shape.
Technical Reports
-
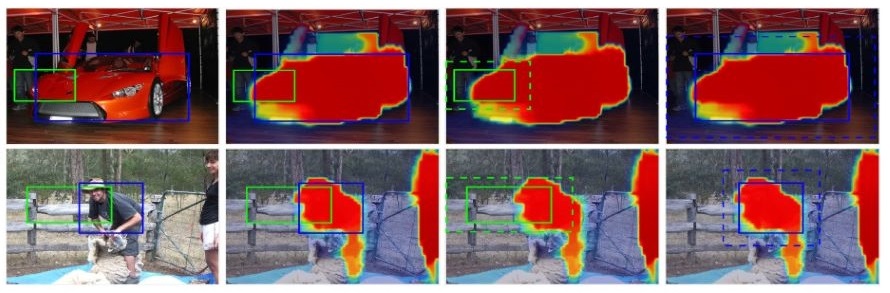 Technical report, 2019.
Technical report, 2019.
We propose a weakly supervised instance segmentation method using image-level labels, leveraging MIL, semantic segmentation, and a novel refinement module.